原文作者:Leslie Lamport origin pdf
译者声明:
本文中的进程(process)表示过程,不是典型意义上计算机的进程
偏序、局部顺序 ←> partial ordering
Abstract
在分布式系统中一个事件发生于另一个事件之前的概念需要被确定,定义为这两个事件的偏序 (partial ordering)。给出一个分布式算法来同步系统的逻辑时钟,时钟可以用来全排序所有的事件。全序可以被用来解决事件同步问题。这个算法还被特化为解决同步物理时钟问题,可以容忍多长的时钟同步延迟。
Introduction
时间是一个基本的概念。可以表示事件发生的顺序。我们说事件发生在 3:15 在时钟表示 3:15,以及 3:16 之前。事件时间顺序的思考无处不在。比如,在航空公司预留系统中,我们声明在票买完之前,可以提供预留服务。与此同时,在考虑分布式系统中的事件时,我们必须慎重审视这个概念。
分布式系统中包含了一系列分离的进程,通过消息互通。网络连接起来的互联网(译者注:此处的互联网不是现在概念上的互联网,本文写于计算机组网早期,比如 ARPA 网络系统)就是一个分布式系统。单独的一台计算也可以被看做分布式系统,其中中控单元,内存单元,I/O 都是分离的进程。如果消息的传递延迟相比于单个进程中的事件之间的事件是不能忽略的,我们就说系统是分布式的。
我们主要考虑空间上分隔的计算机。然而,很多结论可以延伸到更广泛的其他系统中。尤其是,计算机上的多进程系统跟多个计算机组成的分布式系统本质上是相同的,因为都具备事件发生顺序不可预测的特征。
在分布式系统中,有时是说不清楚两个事件的哪个先发生的(译者注:物理时间意义的先)。因此”happened before”的关系实际上应该是两个事件局部顺序。这个问题经常被提出因为人们并没有仔细考虑其背后的意义。
本文中,我们就来讨论如何通过”happened before”关系定义局部顺序,然后给出一个算法来计算所有事件的全部顺序(全序)。这个算法可以提供一个有效的实现分布式系统的机制。我们可以看到通过这个算法的简单应用可以解决同步问题。如果通过该算法获得的排序与用户感知的排序不同,则可能发生非预期的动作。这可以通过引入一个真实的物理时钟来避免。我们同样提出了一个简单的方法来同步这些时钟,并且给出容忍的时钟漂移上限。
The Partial Ordering
大多数人可能这样描述事件 a 在事件 b 之前发生,如果 a 发生的时间早于 b。这就是物理意义上的早于的定义。但是,如果系统有规范说明,应该通过规范说明来定义,如果规范中说明了根据物理时钟,系统必须包括物理时钟,然而,即使系统包含了物理时钟,也可能没有保持与真实事件的时间同步而发生错误。所以,“happened before”关系我们不用物理时钟来定义。
我们首先要将系统定义的更加精确。我们假定系统是由一系列进程构成。每个进程中包含了事件的序列。依赖于具体场景,一个进程中某个子函数的的执行可能是一个事件,或者一条机器指令的执行是一个事件。我们假定这些进程内的事件构成了一个序列,在进程内 a 发生于 b 之前。换句话说,一个进程定义了一个序列事件的全序。看起来事情已经解决了,甚至可以扩展定义将进程分离为子进程,但是我们不这样做。
我们假定发送或者接收消息是一个事件。通过""定义”happened before”
定义. '' 是系统中事件的最小关系,满足以下三个条件:
- 如果和是同一个进程中的事件,而且发生于之前,那么
- 如果是一个进程中发送消息,是另一个进程中接收消息,那么
- 如果并且,那么
两个事件和 ,如果,而且,就说和是并发的。
对于任意事件,。这意味着就可以表示系统中所有事件的局部顺序。
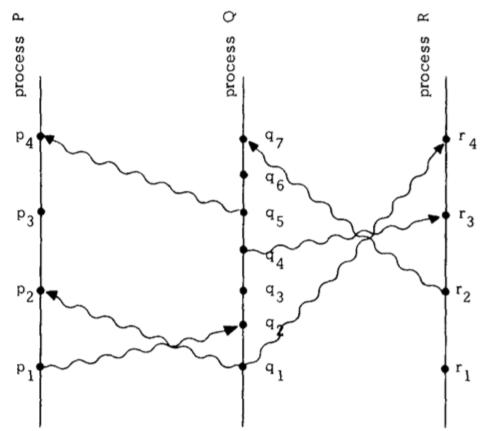
上图对于理解这个定义很有帮助。水平方向表示空间,垂直线表示时间---越高时间越靠后。点表示事件,垂直线表示进程,波浪线表示消息。很容易看出在图中意味着可以将消息传递给,比如
另一个定义是事件可以影响到。两个事件如果不能互相影响就是并发的。即使我们在图中看出在物理时间上早于,进程 P 不知道进程 Q 上发生了事件,直到收到消息(在之前,P 进程最多直到 Q 进程将要发生事件)
This definition will appear quit natural to the reader familiar with the invariant space-time formulation of special relativity, as described for example in [1] or the first chapter of [2]. In relativity, the ordering of events is defined in terms of messages that could be sent. However, we have taken the more pragmatic approach of only considering messages that actually are sent. We should be able to determine if a system performed correctly by knowing only those events which did occur, without knowing which events could have occurred.【这一段不知道怎么翻译。】
Logical Clocks
现在我们来将时钟引入系统。我们开始于很抽象的时钟概念,只用来对一个事件赋值一个数值,这个数值被用来表示事件发生的时间。数学的,我们为每个进程定义一个时钟,函数表示进程中事件的数值。整个系统的时钟通过表示,对于其中的事件的数值使用表示,当事件属于进程,。现在,我们没有将与物理时间绑定起来,所以我们可以将其看做是逻辑时钟而不是物理时钟。他可以使用计数器实现而不需要是时间机制。
现在我们考虑的意味着系统时钟是正确的。但是我们的定义不能基于物理时间,那样我们必须保证物理时钟。我们的目的是根据事件发生的顺序来定义。最强的合理条件是,如果事件发生于事件之前,我们使用下面的形式表示这种关系:
Clock Condition:对于任意事件,如果 ,则。
现在这个条件不可逆,因为那意味着并发事件必须同时发生。在图一中我们看到与是并发的,但是这并不表示它们是同时发生的。
Clock Condtion()满足如下条件:
- 如果事件都是进程的,早于,那么。
- 如果事件是进程发送消息,是进程接收消息,那么
通过 tick 可以将图一划线为图二,条件一意味着同一个进程的两个事件之间要有一条 tick 的线,条件二意味着消息传递线必然与一条 tick 线相交。我们可以调整图二,让 tick 线平行,重画为图三
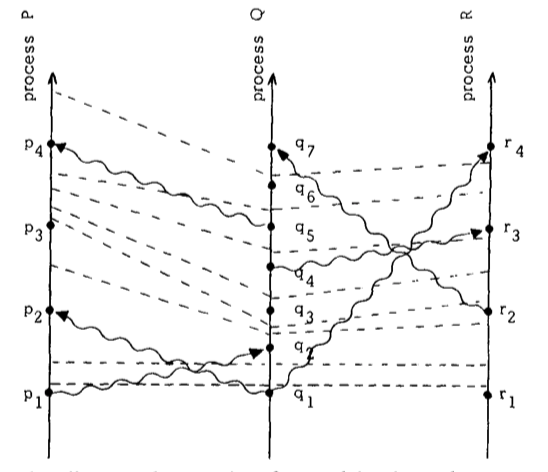
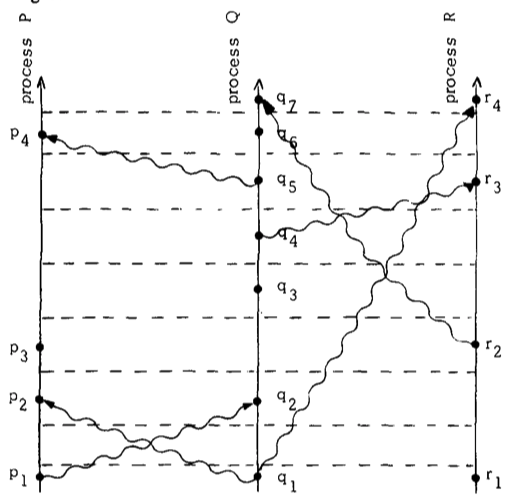
读者可以发现,重画后的图三更清晰表明了各进程之间的事件先后关系。
让我们假定进程就是算法,每个事件是算法的执行命令。我们将阐述如何将时钟引入进程并且满足Clock Condition。进程通过来表示时钟。
为了满足Clock Conditon,条件一很容易,只需要满足以下规则
IR1. 进程在两个连续事件之间的增长
为了满足条件二,我们要求消息包含一个时间戳,其等于消息发出的时间。在收到包含时间戳的消息时,进程必须保证它的时钟大于,数学描述为下面的规则
IR2. 1. 如果事件是进程发送消息,消息包含时间戳 2. 收到消息的进程设置大于等于
这样就可以确保系统的逻辑时钟是正确的。
Ordering the Events Totally
现在我们可以使用满足Cloud Conditon的系统时钟来对系统的所有事件进行全排序。可以简单通过发生时间进行排序。为了避免混淆,我们使用符号表示进程的顺序。为了数学的定义,使用符号表示:如果事件在进程中,事件在进程中,当且仅当 (i) 或者 (ii) 并且 。可以看出如果那么。换句话说,符号是偏序关系在全序中的表示。
依赖于系统时钟,不是唯一的,不同的时钟选择会导致不同的,而偏序关系由系统的事件唯一确定。
知道事件的全序关系对于实现分布式系统非常重要。事实上,实现系统正确的逻辑时钟就是为了获得这样事件的全序关系。全序关系可以解决下面的问题。一个具有多进程的系统,单一的资源,同一时间只能有一个进程使用这单一资源,必须同步信息以免冲突。我们希望找到一个算法分配这个资源满足三个条件
I. 一个已经获取这一资源的进程在另一进程获取前释放该资源 II. 不同进程的资源授权必须按照申请资源的顺序授权 III. 如果每个被授权的进程都释放了资源,那么每个请求都被处理了
我们假定开始该资源被授权给了一个进程。
这是很自然的条件,并且描述了方案的正确性定义。但是条件二无法说明,并发的两个进程谁先获取资源。
要意识到这并非一个简单的问题。使用中心进程来按照接收顺序来授权资源是行不通的,除非有一些额外的假设。比如这种情况,是调度进程,向发送了请求,然后向发送了消息,在没有收到的消息时,也发送了请求到。的请求可以先到达,如果先授权资源给了,那么条件二不满足了。
为了解决这个问题,我们实现了规则 IR1 和 IR2 的系统时钟,然后使用这种时钟来对事件进行全排序。这就可以排序资源所有的请求和释放。有了全序,事情就迎刃而解。
为了简化系统,我们做了一些假设。这些并不是必须的,但是可以避免为了实现细节而分心。我们首先假设任何两个进程,从到的消息会以发送的顺序被收到。并且,每个消息都能被收到(这两个假设可以避免引入消息序列号和消息协议)。我们还假定一个进程可以向其他所有进程发消息。
每个进程维护自己的请求队列,这个请求队列并不会被其他进程看到。我们假定请求队列初始化时包含一个消息:请求资源,是初始化被授权资源的进程,比任何时钟都小。
算法可以通过下面的五条规则定义。为了方便,每条规则定义的动作只能构成一个事件。
- 为了请求资源,进程发送消息:向其他所有进程请求资源,将消息放入自己的请求队列,是消息的时间戳
- 当进程收到消息,也将其放入自己的消息队列,回一个 ack
- 为了释放资源,进程从消息队列删除消息,然后发送一个释放资源的消息给其他所有进程
- 当进程收到释放资源的消息,也将其从自己的消息队列删除
- 进程满足下面两个条件时被授权资源:(1). 消息队列中有 (2) 收到了其他所有的进程的消息晚于(注意到这两个条件只需要自己就可以确定)
证明满足了条件 I~III 还是比价容易。首先,规则 5 的第二点,结合先前消息按序收到的假设,保证了在发出请求前已经收到了其他的所有消息。因为规则 3 和 4 只是从请求队列删除消息,容易看出满足了条件 I。条件 II 可以从全序中得出。规则 2 保证了请求资源之后,规则 5 的第二点能达到。规则 3 和 4 表明如果一个被授权资源的进程释放了,规则 5 的第一点能达到,所以证明了条件 III
这是一个分布式算法。每个进程都按照这些规则动作,没有中心进程来协调它们。这个方法可以被扩展为任何多进程中的同步方案。这个同步方案可以被称为State Machine,包含了一系列可能的命令,一系列可能的状态,和一个函数。关系在状态表示执行命令状态转移为。我们的例子中,命令包含了的所有请求资源和释放资源的命令,状态包含了一个等待请求命令的队列,队列头的请求就是当前被授权的进程。执行一个请求命令在队列尾部入队请求,执行释放命令在头部出队请求。
每个进程分离的使用所有进程的请求仿真状态机的转移。因为所有进程通过时间戳排序命令,所有进程有相同顺序的命令,所以最终会达成同步状态。一个进程在执行完所有进程小于的命令才会执行的命令。这个算法很清楚,我们不会再解释它。
但是,这个方案要求所有进程参与进来,一个进程必须获得其他所有进程的命令,任意一个进程出问题,整个系统就会跟着出问题,无法维护状态机。
这个问题很难解决,这就是本文下面要讨论的。我们要建立在物理时间上下文时的错误概念。没有物理时间,就无法区分一个进程是挂了还是只是偶尔暂停。用户可以在系统只是响应比较慢的时候说系统”crashed”了。当单个进程或者消息通信出问题,有方法规避。
Anomalous Behavior
我们的资源规划算法通过请求的全序来解决。这会导致下面的错误行为。考虑一个全国联网的计算机系统,假设一个人在计算机 A 上发出请求 A,然后给另一个城市的朋友打电话让他在计算机 B 上发出请求 B。很有可能请求 B 的时间戳更小,从而排序在 A 之前。系统不知道请求 A 应该在 B 之前,因为排序消息依赖于系统的消息传递。
让我们剖析这个系统的问题。使用符号表示系统中的所有事件。让我们引入一个事件集合,包含中的事件和与其相关联的外部事件,比如上面例子的电话呼叫。仍然使用表示事件集合中的偏序关系。我们例子中,我们有,但是。显然没有算法可以只根据中的事件来确定之间的偏序关系。
有两种可能的方法来避免这个问题。第一个是在系统中引入确定关系的一些必要信息,在上面的例子中,发出的请求打上时间戳,请求的时间戳要大于。
第二个是构造一个满足下面条件的系统时钟。
Strong Clock Condition。对于中的任意事件,如果, 则
这个比Clock Condition条件更强。
宇宙的秘密之一就是,可以构造这种物理时钟,彼此分离的运行,但是却可以满足Strong Clock Condition。
Physical Clocks
让我们将物理时钟与上面的理论结合,让表示在物理时间看到的时钟,为了数学上的方便,我们假设时钟是连续的而不是按照离散的 tick。数学的描述就是,是连续的,这个函数关于的微分表示了在时间时钟的快慢程度。
为了使得时钟与物理时钟尽可能一致,要让其微分尽可能为 1. 数学描述为下面的条件
PC1. 存在一个常数 ,对于所有的: 。的典型值为
然而让所有分离的时钟以正确近似的速率运行是不够的的。它们还必须尽可能同步,对于所有来说,同样可以使用小常数来表示
PC2. 对于所有的,
让我们来使用图二来表征物理时间,图三的画法中,水平线对应的每条进程的值是要小于
因为不可能存在两个完全一致速率运行的时钟,总会发生漂移,我们必须有一个算法使得 PC2 的条件得以满足。首先,我们必须确定两个小常数多小才能避免 Anomalous Behavior。我们必须使得系统中的相关物理事件满足Strong Clock Condition。首先假定进程内的顺序不会有问题,那么我们只用考虑不同进程事件的关系即可。
一个进程中的事件发生在时间,然后另一个进程中的事件,两个事件满足,则发生的时间在之后。换句话说,小于进程间通信的时间。我们可以选择等于光速传播最短距离的事件。当然,这取决于系统中的消息如何传递。
为了规避 Anomalous Behavior,我们必须保证对于任意,。综上,我们可以得出,当时钟被重置的时候,只能往前而不能倒退(倒退会导致 PC1 不满足),PC1 需要 ,根据 PC2,如果不等式成立,可以推导出。
不等式和 PC1,2 得到 Anomalous Behavior 不可能发生。
现在我们描述算法。使用表示在物理时间发送时间被接收的消息。定义为消息的延迟。接收消息的进程不知道这个延迟。但是我们假定接收进程知道最小延迟。使用表示消息的不可预知延迟。
将 IR1 和 IR2 与物理时钟结合后扩展为 IR1’ IR2’
IR1’ 对于每个,如果在物理时间没有收到消息,则在是可微的,并且
IR2’ (a) 如果在时间发送了消息,中包含了时间戳 (b) 在进程在物理时间收到消息,将设置为
尽管规则中有物理时间的参数,但是每个进程只需要知道自己的物理时钟读数,以及消息中的时间戳。为了方便数学表述,我们假设了同一进程中的事件不会在同一物理时间发生。
【译者注:】通过一个数理公式证明了满足 PC2,这里省去翻译,数理公式的证明在 Appendix,同样略去
Conslusion
定义了”happened before”的概念,偏序关系和全序关系。并且阐述了全序关系对于分布式系统的重要性,提出了逻辑时钟的算法
逻辑时钟有时是有问题的,可以通过引入物理时钟解决,并且物理时钟是可能漂移的
在分布式系统中,认识到事件之间的偏序关系是非常重要的。我们也认为这个 idea 在多进程系统同样重要。可以帮助人们理解多进程设计的基本问题,以及如何解决。
Appendix
略
参考文章:
- https://lrita.github.io/2018/10/24/lamport-logical-clocks-vector-lock/
- 狭义相对论与分布式系统中的时间 https://www.jianshu.com/p/0c79d650d13f
- 阐述了分布式系统中时间的本质,探索了分布式理论的本质
- 提出了 Logical Clock 算法,是后续 Vector Clock,HLC(混合逻辑时钟,包含了 logic clock, physical clock) 等的基础
- 提出了 Replicated State Machine 的理念,是后续 Paxos 及其应用的基础
- 设计了无中心的分布式临界资源算法,是后续多种无中心分布式算法的鼻祖
- 设计了时间同步的雏形算法,后续 NTP 等的基础
- 阿里数据库的 HLC https://database.51cto.com/art/201911/606198.htm
- https://lrita.github.io/2018/10/19/communication-model-in-distribution/
- http://zhangtielei.com/posts/blog-distributed-causal-consistency.html 【推荐】
- timestamp