TCP
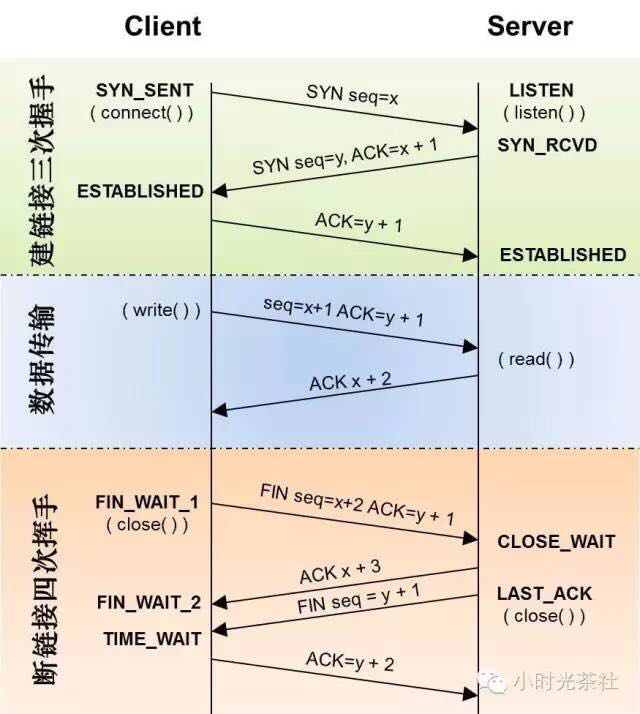 TCP state
TCP state
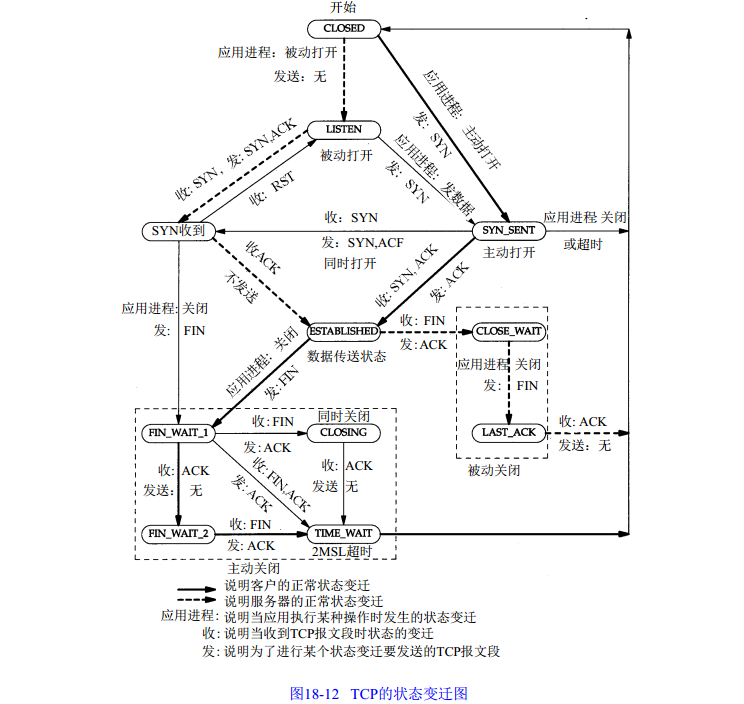
![]()
TCP 链接初始化序号能否固定
如果 ISN(Intiial Sequence Number)能固定,会出现 c/s 之间的疑惑,所以 RFC793 中,建议 ISN 和一个假时钟绑在一次,这个时钟每 4us 加一,直到超过 2^32 ,这样需要 4 个小时才会出现 ISN 回绕问题,几乎可以保证每个新链接的 ISN 不会与旧链接冲突
初始化链接 SYN 超时
如果 c 发送 syn 到 server 之后挂了,server 需要一个超时机制断开链接,否则 server 的 syn 链接队列耗尽。目前 Linux 默认会重发 5 次 SYN-ACK 包,间隔重试时间翻倍(1,2,4,8,16s),总共 31s,第 5 次发出后等 32s 超时,就会断开这个连接。所以攻击者如果短时间发送大量 SYN,会使服务器失效,称为 SYN flood 攻击。Linux 提供了几个配置调整: tcp_syncookies,tcp_synack_retries, tcp_max_syn_backlog, tcp_abort_on_overflow
四次挥手能否变成三次
可能。TCP 是全双工通信,cli 没有数据发给 server 之后,可以发送 FIN 包,但是如果这个时候 server 还在发送数据给 cli,就需要四次挥手,但是如果 server 在收到 cli 的 FIN 包之后,也没数据发给 cli,可以将 ACK 和 FIN(发给 cli)一起发送给 cli,然后等 cli 回一个 ack,三次就完成了断开连接。
TIME_WAIT 状态的问题
tcp 主动关闭连接的一方会最后进入 TIME_WAIT 状态。
为什么需要 TIME_WAIT
- 主动发 FIN 包的一方需要进入 TIME_WAIT 以重发被动关闭方 FIN 的 ACK,因为被动关闭方发的 FIN 如果没有收到 ACK ,会重发 FIN,如果没有 TIME_WAIT 状态,主动关闭方就不认识重发的 FIN,会回复 RST,在被动关闭方就会报错。
- 防止已经断开的连接1中在链路中残留的FIN包终止掉新的连接2(重用了连接1的所有的5元素(源IP,目的IP,TCP,源端口,目的端口)),这个概率比较低,因为涉及到一个匹配问题,迟到的FIN分段的序列号必须落在连接2的一方的期望序列号范围之内,虽然概率低,但是确实可能发生,因为初始序列号都是随机产生的,并且这个序列号是32位的,会回绕。
- 防止链路上已经关闭的连接的残余数据包(a lost duplicate packet or a wandering duplicate packet) 干扰正常的数据包,造成数据流的不正常。这个问题和2)类似。
带来的问题
一个连接进入TIME_WAIT状态后需要等待2*MSL(一般是1到4分钟)那么长的时间才能断开连接释放连接占用的资源,会造成以下问题:
- 作为服务器,短时间内关闭了大量的Client连接,就会造成服务器上出现大量的TIME_WAIT连接,占据大量的tuple,严重消耗着服务器的资源
- 作为客户端,短时间内大量的短连接,会大量消耗的Client机器的端口,毕竟端口只有65535个,端口被耗尽了,后续就无法在发起新的连接了 所以当客户端需要连接本机的服务时,优先选用域 socket
TIME_WAIT 状态连接的快速回收和重用
- TIME_WAIT快速回收: linux下开启TIME_WAIT快速回收需要同时打开tcp_tw_recycle和tcp_timestamps(默认打开)两选项。Linux下快速回收的时间为3.5 * RTO(Retransmission Timeout),而一个RTO时间为200ms至120s。开启快速回收TIME_WAIT,可能会带来(问题一、)中说的三点危险,为了避免这些危险,要求同时满足以下三种情况的新连接要被拒绝掉。[1]. 来自同一个对端Peer的TCP包携带了时间戳。 [2].之前同一台peer机器(仅仅识别IP地址,因为连接被快速释放了,没了端口信息)的某个TCP数据在MSL秒之内到过本Server [3].Peer机器新连接的时间戳小于peer机器上次TCP到来时的时间戳,且差值大于重放窗口戳(TCP_PAWS_WINDOW) 初看起来正常的数据包同时满足下面3条几乎不可能, 因为机器的时间戳不可能倒流的,出现上述的3点均满足时,一定是老的重复数据包又回来了,丢弃老的SYN包是正常的。到此,似乎启用快速回收就能很大程度缓解TIME_WAIT带来的问题。但是,这里忽略了一个东西就是NAT。在一个NAT后面的所有Peer机器在Server看来都是一个机器,NAT后面的那么多Peer机器的系统时间戳很可能不一致,有些快,有些慢。这样,在Server关闭了与系统时间戳快的Client的连接后,在这个连接进入快速回收的时候,同一NAT后面的系统时间戳慢的Client向Server发起连接,这就很有可能同时满足上面的三种情况,造成该连接被Server拒绝掉。所以,在是否开启tcp_tw_recycle需要慎重考虑了
- TIME_WAIT重用 linux上比较完美的实现了TIME_WAIT重用问题。只要满足下面两点中的一点,一个TW状态的四元组(即一个socket连接)可以重新被新到来的SYN连接使用 [1]. 新连接SYN告知的初始序列号比TIME_WAIT老连接的末序列号大 [2]. 如果开启了tcp_timestamps,并且新到来的连接的时间戳比老连接的时间戳大 要同时开启tcp_tw_reuse选项和tcp_timestamps 选项才可以开启TIME_WAIT重用,还有一个条件是:重用TIME_WAIT的条件是收到最后一个包后超过1s。细心的同学可能发现TIME_WAIT重用对Server端来说并没解决大量TIME_WAIT造成的资源消耗的问题,因为不管TIME_WAIT连接是否被重用,它依旧占用着系统资源。即便如此,TIME_WAIT重用还是有些用处的,它解决了整机范围拒绝接入的问题,虽然一般一个单独的Client是不可能在MSL内用同一个端口连接同一个服务的,但是如果Client做了bind端口那就是同个端口了。时间戳重用TIME_WAIT连接的机制的前提是IP地址唯一性,得出新请求发起自同一台机器,但是如果是NAT环境下就不能这样保证了,于是在NAT环境下,TIME_WAIT重用还是有风险的。 有些同学可能会混淆tcp_tw_reuse和SO_REUSEADDR 选项,认为是相关的一个东西,其实他们是两个完全不同的东西,可以说两个半毛钱关系都没。tcp_tw_reuse是内核选项,而SO_REUSEADDR用户态的选项,使用SO_REUSEADDR是告诉内核,如果端口忙,但TCP状态位于 TIME_WAIT ,可以重用端口。如果端口忙,而TCP状态位于其他状态,重用端口时依旧得到一个错误信息, 指明Address already in use”。如果你的服务程序停止后想立即重启,而新套接字依旧使用同一端口,此时 SO_REUSEADDR 选项非常有用。但是,使用这个选项就会有(问题二、)中说的三点危险,虽然发生的概率不大
UDP
UDP 报文大小
UDP 报文大小的影响因素,主要有以下3个
- UDP协议本身,UDP协议中有16位的UDP报文长度,那么UDP报文长度不能超过2^16=65536
- 以太网(Ethernet)数据帧的长度,数据链路层的MTU(最大传输单元)
- socket的UDP发送缓存区大小
UDP数据包最大长度根据 UDP 协议,从 UDP 数据包的包头可以看出,UDP 的最大包长度是2^16-1的个字节。由于UDP包头占8个字节,而在IP层进行封装后的IP包头占去20字节,所以这个是UDP数据包的最大理论长度是2^16 - 1 - 8 - 20 = 65507字节。如果发送的数据包超过65507字节,send或sendto函数会错误码1(Operation not permitted, Message too long),当然啦,一个数据包能否发送65507字节,还和UDP发送缓冲区大小(linux下UDP发送缓冲区大小为:cat /proc/sys/net/core/wmem_default)相关,如果发送缓冲区小于65507字节,在发送一个数据包为65507字节的时候,send或sendto函数会错误码1(Operation not permitted, No buffer space available)。
UDP数据包理想长度:理论上 UDP 报文最大长度是65507字节,实际上发送这么大的数据包效果最好吗?我们知道UDP是不可靠的传输协议,为了减少 UDP 包丢失的风险,我们最好能控制 UDP 包在下层协议的传输过程中不要被切割。相信大家都知道MTU这个概念。 MTU 最大传输单元,这个最大传输单元实际上和链路层协议有着密切的关系,EthernetII 帧的结构 DMAC + SMAC + Type + Data + CRC 由于以太网传输电气方面的限制,每个以太网帧都有最小的大小64字节,最大不能超过1518字节,对于小于或者大于这个限制的以太网帧我们都可以视之为错误的数据帧,一般的以太网转发设备会丢弃这些数据帧。由于以太网 EthernetII 最大的数据帧是1518字节,除去以太网帧的帧头(DMAC目的 MAC 地址48bit=6Bytes+SMAC源 MAC 地址48bit=6Bytes+Type域2bytes)14Bytes和帧尾CRC校验部分4Bytes那么剩下承载上层协议的地方也就是Data域最大就只能有1500字节这个值我们就把它称之为MTU。 在下层数据链路层最大传输单元是1500字节的情况下,要想IP层不分包,那么UDP数据包的最大大小应该是1500字节 – IP头(20字节) – UDP头(8字节) = 1472字节。不过鉴于Internet上的标准MTU值为576字节,所以建议在进行Internet的UDP编程时,最好将UDP的数据长度控制在 (576-8-20)548字节以内。
UDP server 端收到的可能不是 client 发送的数据包顺序,但是如果没有出错,收到的数据包个数和每个数据包大小跟发送的是一致的。(有届,无序)
丢包
如果不考虑下层协议出问题,还有以下可能
- UDP socket缓冲区满造成的UDP丢包:通过 cat /proc/sys/net/core/rmem_default 和cat /proc/sys/net/core/rmem_max可以查看socket缓冲区的缺省值和最大值。如果socket缓冲区满了,应用程序没来得及处理在缓冲区中的UDP包,那么后续来的UDP包会被内核丢弃,造成丢包。在socket缓冲区满造成丢包的情况下,可以通过增大缓冲区的方法来缓解UDP丢包问题。但是,如果服务已经过载了,简单的增大缓冲区并不能解决问题,反而会造成滚雪球效应,造成请求全部超时,服务不可用。
- UDP socket缓冲区过小造成的UDP丢包:如果Client发送的UDP报文很大,而socket缓冲区过小无法容下该UDP报文,那么该报文就会丢失。
- ARP缓存过期导致UDP丢包:ARP 的缓存时间约10分钟,APR 缓存列表没有对方的 MAC 地址或缓存过期的时候,会发送 ARP 请求获取 MAC 地址,在没有获取到 MAC 地址之前,用户发送出去的 UDP 数据包会被内核缓存到 arp_queue 这个队列中,默认最多缓存3个包,多余的 UDP 包会被丢弃。被丢弃的 UDP 包可以从 /proc/net/stat/arp_cache 的最后一列的 unresolved_discards 看到。当然我们可以通过 echo 30 > /proc/sys/net/ipv4/neigh/eth1/unres_qlen 来增大可以缓存的 UDP 包。
UDP 的丢包信息可以从 cat /proc/net/udp 的最后一列drops中得到,而倒数第四列 inode 是丢失 UDP 数据包的 socket 的全局唯一的虚拟i节点号,可以通过这个 inode 号结合 lsof ( lsof -P -n | grep 25445445)来查到具体的进程。
通常情况下,TCP 对于网络的容忍程度要更高,只有比如流媒体等特殊应用场景(流媒体对于丢包有较高的容忍性,并且不希望自动重传的机制会增加延迟,在算法上设计了冗余恢复媒体数据)会采用 UDP 来在应用层设计算法和传输协议。
通常情况下,UDP的使用范围是较小的,在以下的场景下,使用UDP才是明智的:
- 实时性要求很高,并且几乎不能容忍重传; 例子:NTP协议,实时音视频通信,多人动作类游戏中人物动作、位置。
- TCP实在不方便实现多点传输的情况;
- 需要进行NAT穿越;
- 对网络状态很熟悉,确保udp网络中没有氓流行为,疯狂抢带宽;
- 熟悉UDP编程。