什么是零拷贝
为了更好地理解解决了什么问题,首先要理解问题本身。我们来看下下面的代码发生了什么
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
看起来简单,你可能觉得两次系统调用也不是多大的开销。实际上,远比你想象中的大。这两次系统调用之下,数据拷贝了四次,并且还有内核态和用户态之间的上下文切换(实际上这个进程更复杂,但是先保持这种程度的简化)。为了更好地了解这个进程的调用,看下图
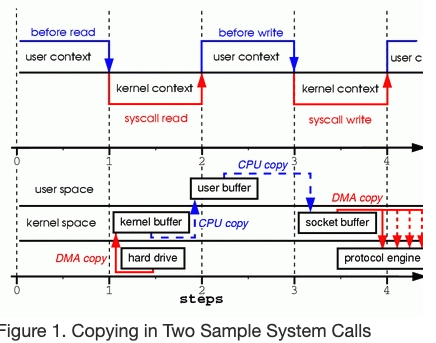
第一步:read 系统调用发生了用户态到内核态的切换。第一次拷贝由DMA执行,从 disk 读取文件内容到内核空间的 buffer
第二步:数据从内核空间的 buffer 拷贝到用户空间的 buffer,然后 read 系统调用 return。return 又发生了内核态到用户态的切换。现在数据存储在用户态的 buffer 中
第三步:write 系统调用发生了用户态到内核态的切换。第三次拷贝从用户空间 buffer 到内核空间 buffer,这次内核空间的buffer 与 socket 关联
第四步:write 系统调用 return,触发了第四次上下文切换。单独异步的拷贝由DMA控制将数据从内核空间的 buffer 拷贝到协议栈中。你可能会问“什么叫独立异步?数据不是在return的时候就传输完成了吗?”事实上,return 并不保证传输完成;甚至不保证传输开始。可能在这次调用之前队列中有很多包,除非硬件驱动实现了优先队列,并且本次数据在第一优先级的队列中
正如你所看到的,很多数据拷贝实际本不必要发生。有些拷贝可以规避掉来减少开销提升程序性能。对一个驱动开发者,硬件实际有很多增强功能。有些硬件支持 bypass 主存,直接从将数据传输到其他设备。这个特性可以减少系统存储中的拷贝,但并不是所有硬件都支持。还有一个问题就是从disk得到数据需要为了网络重新封装,这带来了复杂性。为了减少开销,我们可以从减少内核空间和用户空间之间的拷贝开始。
mmap
一个方法就是避免使用read,而使用 mmap
tmp_buf = mmap(file, len);
write(socket, tmp_buf, len);
为了更好地理解这个过程,看下图
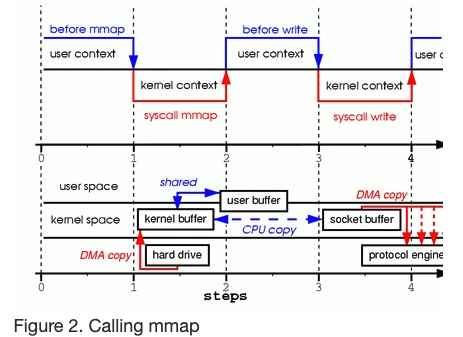
第一步:mmap 系统调用使得文件内容通过 DMA 从disk 拷贝到内核空间的buffer,这个buffer可以直接在用户空间访问,不需要拷贝到用户空间
第二步:write 系统调用使得内核将内核空间buffer中的数据拷贝到 socket 关联的内核buffer中
第三步:第三次拷贝是 DMA 将socket buffer中的数据拷贝到协议栈中
通过使用 mmap,我们减少了一次使用 CPU 的拷贝。当大量数据传输时这比较有用,但并不是没有代价,有些隐藏的问题其实。当另一个进程也mmap到了同一个文件,然后对其进行了写入操作。上面代码的 write 就会被 SIGBUS 中断。这个信号默认的行为是杀死进程并coredump -- 这个操作对于网络服务器恨不能接受。有两种方法解决这个问题
第一个是定义一下 SIGBUS 的信号处理程序,直接return。这样 write 系统调用就会返回中断前写入的字节数,然后 errno 被设置为成功。这是个垃圾方案,无视问题,因为 SIGBUS 实际表示进程发生了严重错误,不应该无视
第二个是使用内核的文件租约(也叫“乐观锁”)。这是正确的解决方案。你可以从内核请求 read/write lease,当另一个进程视图对同一个文件进行截断时,内核会发送 RT_SINGAL_LEASE信号给有租约的进程,告诉你内核正在打断你的租约。你的写请求就会在程序访问无效地址之前被中断而不会导致 SIGBUS。write的返回值就是已经写入的字节数,errno被设置为成功,代码如下
if (fcntl(fd, F_SETSIG, RT_SIGNAL_LEASE) == -1) {
perror("kernel lease set signal");
return -1;
}
/*l_type can be F_RDLCK F_WRLCK*/
if (fcntl(fd, F_SETLEASE, l_type)) {
peror("kernel lease set type");
return -1;
}
你应该在 mmap file之前获取租约,然后完成写入后主动放弃租约。通过调用 fcntl(F_SETLEASE, F_UNLCK)
Sendfile
在内核2.1版本,sendfile 系统调用简化了将数据从文件传输到socket的方法,不仅减少了数据拷贝,还减少了内核与用户空间的上下文切换
sendfile(socket, file, len);
为了更好地理解底层过程,如下图
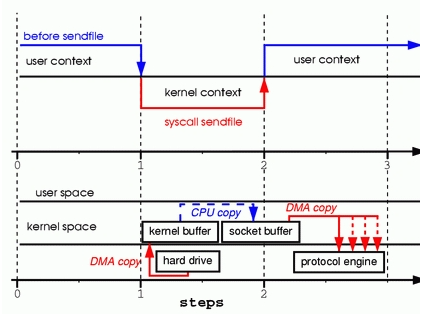
第一步:sendfile 系统调用使得文件内容通过 DMA 拷贝到内核buffer,然后数据被内核拷贝到 socket buffer
第二步:第三次拷贝 DMA 控制从 socket buffer 拷贝到协议栈
你可能想知道如果另一个进程截断了这个文件,sendfile会发生什么。如果没有注册信号处理函数,sendfile 调用会返回已经传输的字节,errno被设置为成功
如果 sendfile 之前获取了文件租约,行为相同。同时sendfile return前会有 RT_SIGNAL_LEASE 信号
sendfile + gather(hardware)
如此说来,我们已经避免了内核进行多次拷贝,但是还有一次拷贝,可以也避免吗?当然,但是需要硬件的支持。为了消除内核的所有拷贝,需要网卡支持 gather 操作。内核2.4版本引入了socket对这种操作的支持,这种方法不需要内核态切换,也不需要处理器进行数据拷贝。同时用户代码不变
sendfile(socket, file, len);
底层流程如下图
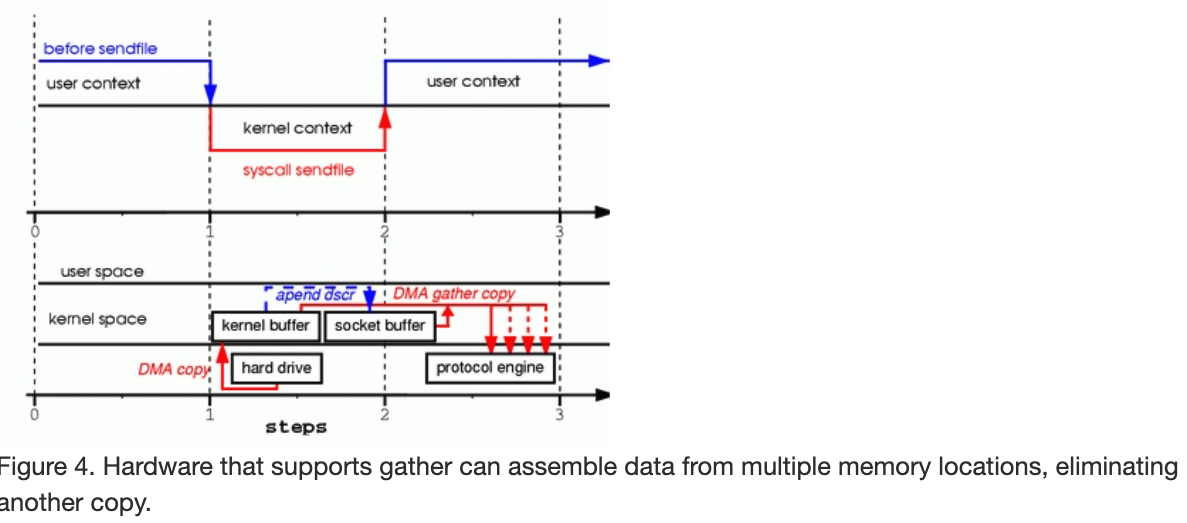
第一步:sendfile 系统调用可以将文件内容通过 DMA 拷贝到内核 buffer
第二步:没有数据被拷贝到 socket buffer。socket 文件描述符只有数据的长度信息。DMA 直接将数据从kernel buffer 拷贝到协议栈
因为数据从 disk 到主存的拷贝和从主存到总线的拷贝,有些人觉得这也不是零拷贝。这只是从操作系统角度的零拷贝,因为在操作系统中只有一个buffer。当使用零拷贝时,性能提升还来自,比如更少的内核用户态切换,更少的 CPU cache 污染以及不需要 CPU 校验
现在我们知道了什么是零拷贝,练习些代码吧。你可以下载完整代码。
splice
sendfile 只适用于将数据从文件拷贝到socket(依赖于具体实现,linux系统可以从文件到文件),而且使用 gather 需要硬件的支持。Linux 在2.6.17版本中实现了 splice 系统调用,不需要硬件支持,实现了两个文件描述符之间的数据零拷贝。
Copysplice(fd_in, off_in, fd_out, off_out, len, flags);
splice 系统调用在内核空间的 buffer 和 socket buffer 之间建立了管道,避免了两者之间的 CPU 拷贝操作
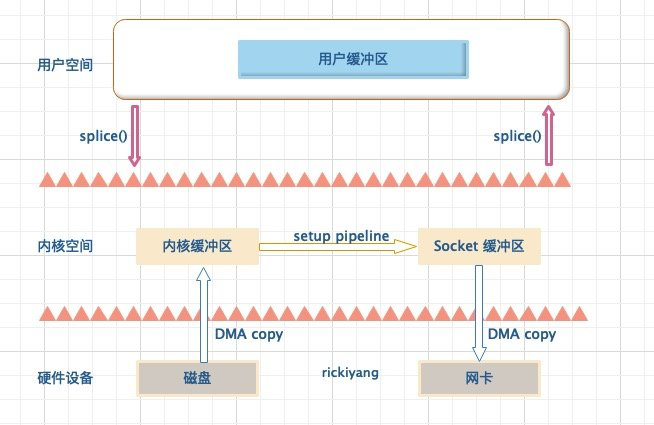
基于 splice 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换,0 次 CPU 拷贝以及 2 次 DMA 拷贝,用户程序读写数据的流程如下:
- 用户进程通过
splice()函数向内核(kernel)发起系统调用,上下文从用户态 (user space) 切换为内核态(kernel space); - CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间 (kernel space) 的读缓冲区 (read buffer);
- CPU 在内核空间的读缓冲区 (read buffer) 和网络缓冲区(socket buffer)之间建立管道 (pipeline);
- CPU 利用 DMA 控制器将数据从网络缓冲区 (socket buffer) 拷贝到网卡进行数据传输;
- 上下文从内核态 (kernel space) 切换回用户态 (user space),splice 系统调用执行返回。
splice 拷贝方式也同样存在用户程序不能对数据进行修改的问题。除此之外,它使用了 Linux 的管道缓冲机制,可以用于任意两个文件描述符中传输数据,但是它的两个文件描述符参数中有一个必须是管道设备。
写时复制
在某些情况下,内核缓冲区可能被多个进程所共享,如果某个进程想要这个共享区进行 write 操作,由于 write 不提供任何的锁操作,那么就会对共享区中的数据造成破坏,写时复制的引入就是 Linux 用来保护数据的。
写时复制指的是当多个进程共享同一块数据时,如果其中一个进程需要对这份数据进行修改,那么就需要将其拷贝到自己的进程地址空间中。这样做并不影响其他进程对这块数据的操作,每个进程要修改的时候才会进行拷贝,所以叫写时拷贝。这种方法在某种程度上能够降低系统开销,如果某个进程永远不会对所访问的数据进行更改,那么也就永远不需要拷贝。
缺点:
需要 MMU 的支持,MMU 需要知道进程地址空间中哪些页面是只读的,当需要往这些页面写数据时,发出一个异常给操作系统内核,内核会分配新的存储空间来供写入的需求。
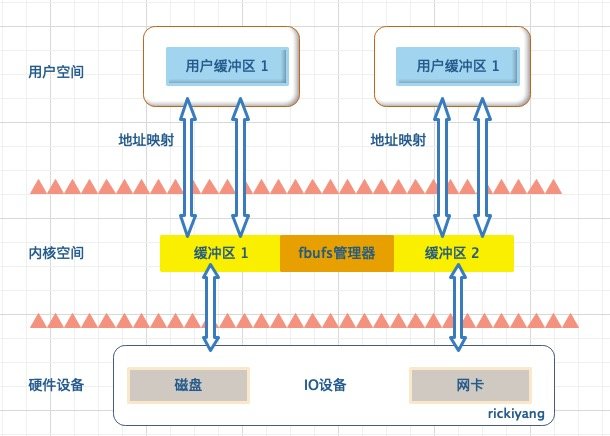
缓冲区共享
缓冲区共享方式完全改写了传统的 I/O 操作,传统的 Linux I/O 接口支持数据在应用程序地址空间和操作系统内核之间交换,这种交换操作导致所有的数据都需要进行拷贝。
如果采用 fbufs 这种方法,需要交换的是包含数据的缓冲区,这样就消除了多余的拷贝操作。应用程序将 fbuf 传递给操作系统内核,这样就能减少传统的 write 系统调用所产生的数据拷贝开销。
同样的应用程序通过 fbuf 来接收数据,这样也可以减少传统 read 系统调用所产生的数据拷贝开销。
fbuf 的思想是每个进程都维护着一个缓冲区池,这个缓冲区池能被同时映射到用户空间 (user space) 和内核态 (kernel space),内核和用户共享这个缓冲区池,这样就避免了一系列的拷贝操作。
缺点:
缓冲区共享的难度在于管理共享缓冲区池需要应用程序、网络软件以及设备驱动程序之间的紧密合作,而且如何改写 API 目前还处于试验阶段并不成熟。
Linux零拷贝对比
无论是传统 I/O 拷贝方式还是引入零拷贝的方式,2 次 DMA Copy 是都少不了的,因为两次 DMA 都是依赖硬件完成的。下面从 CPU 拷贝次数、DMA 拷贝次数以及系统调用几个方面总结一下上述几种 I/O 拷贝方式的差别。
| 拷贝方式 | CPU拷贝 | DMA拷贝 | 系统调用 | 上下文切换 |
|---|---|---|---|---|
| 传统方式(read + write) | 2 | 2 | read / write | 4 |
| 内存映射(mmap + write) | 1 | 2 | mmap / write | 4 |
| sendfile | 1 | 2 | sendfile | 2 |
| sendfile + DMA gather copy | 0 | 2 | sendfile | 2 |
| splice | 0 | 2 | splice | 2 |