PaxosStore: High-availability Storage Made Practical in WeChat
Posted 2021-03-17 00:00:00 ‐ 21 min read
摘要
本文中,我们推出了 PaxosStore,一种支持微信综合业务的高可用存储系统。在存储层使用了组合设计利用多种存储引擎来适配不通的存储模型。PaxosStore 使用 Paxos 共识协议作为中间层,统一了对于底层多个存储引擎的访问。这有助于调整、维护,以及对于存储系统的扩缩容。根据我们在工程实践中的经验,在实际中实现一套可用的一致性读写协议比理论上要复杂很多。为了克服工程的复杂性,我们提出了 Paxos-based 存储的多层协议栈,其中 PaxosLog,协议中的关键数据结构,被设计为桥接从面向程序的一致性读写到面向存储的 Paxos 过程。此外,我们还提供了基于 Paxos 的优化,可以更有效的具备容错能力。本文讨论主要侧重务实的解决方案,这可能是构建分布式存储系统的关键。
1. 介绍 (Introduction)
微信是最受欢迎的移动应用之一,每天拥有 7 亿活跃用户。由微信提供的服务包括 IM,社交网络,移动支付,第三方授权等。各种微信的后端服务由不同的团队开发。尽管业务逻辑的多样性,大多数后端组件需要可靠的存储来支撑。最开始每个开发团队随机选择现成的存储方案来实现原型。然而,在生产系统中,各种碎片化的存储系统维护成本极高,而且难以扩展。这种现状呼吁着一个通用的存储系统提供个各种微信业务使用,而 PaxosStore 就是微信的第二代存储系统
这个存储服务需要满足以下要求。首先,大数据的 3 大 V(volume,velocity,variety)是存在的。每天平均产生 1.5TB 的数据,其中包含各种类型的内容,包括文本消息,图像,音频,视频,财务交易,社交网站帖子等。白天的应用的查询速率达到每秒万条。尤其是,单记录访问占主要使用情况。其次,高可用在存储服务中必须是一等公民。大多数服务依赖 PaxosStore(比如,点对点消息,群消息,浏览社交网络帖子等)。可用性对于用户体验是至关重要的。微信的大多数应用要求 PaxosStore 的延迟小于 20ms。而且跨城市的访问也要有这种延迟要求。
除了建设 PaxosStore 提供高可用服务,还面临以下挑战:
- 有效性和高效的共识保证。 PaxosStore 核心上使用 Paxos 算法达成共识。尽管理论上的 Paxos 算法提供了共识保证,但是实现的复杂性(例如需要维护复杂的状态机)以及运行时的开销(例如同步的带宽)使其不足以全面支持微信的服务
- 弹性以及低延迟。 PaxosStore 要求在城市规模提供低延迟的读写。在运行时需要支撑巨大的负载
- 自动跨数据中心的容错能力。 在微信的生产环境,PaxosStore 全球跨数据中心部署了成千上百的服务器。在这种大规模系统中,硬件故障和网络中断并不罕见。容错能力要求快速的故障检测和不影响系统的恢复。
PaxosStore 设计并实施为微信后端高可用性存储的解决方案。在存储层中采用组合设计,接入了不同的存储引擎来适应不同的存储模型。PaxosStore 使用 Paxos 共识协议作为中间层统一了对于底层存储引擎的访问。Paxos-based 的存储协议可扩展支持各种暴露于应用程序的数据结构。此外,PaxosStore 采用 leaseless design(译者注:无租约),这有利于改善系统的可用性以及容错能力。
论文的主要贡献如下:
- 我们介绍了 PaxosStore 的设计,重点阐述了一致性读写协议的构建及其运作方式。通过从存储层中解耦出一致性协议,PaxosStore 拥有很好的可扩展性,可以给为不同存储模型构建的多种存储引擎提供支持。
- 根据 PaxosStore 的设计,我们进一步论述了容错系统以及关于数据恢复的细节。 文中描述的技术已在大型生产环境中实现了全面应用,它们使 PaxosStore 在微信所有的生产应用中达到了 99.9999% 的可用性(此结果是通过对 6 个月的运行数据进行统计得出的)。
- 在日益成长的微信业务背后, PaxosStore 已经为其提供了两年多的支持。基于这些实践经验,我们探讨了 PaxosStore 设计上的取舍,并给出了我们的应用实践所得到的实验评估结果。
文章剩余的内容组织如下。首先在第二节详细阐述了设计细节和 PaxosStore 的架构,然后在第三节描述了容错系统和数据恢复技术。在第四节讨论 PaxosStore 的实现关键点。在第五节,对 PaxosStore 进行了性能测试并收集了运行系统中的数据来展示。在第六节讨论了相关研究,最后第七节总结了本文以及在构建 PaxosSore 系统的得到的经验。
2. 设计 (Design)
2.1 架构 (Overall Architecture)
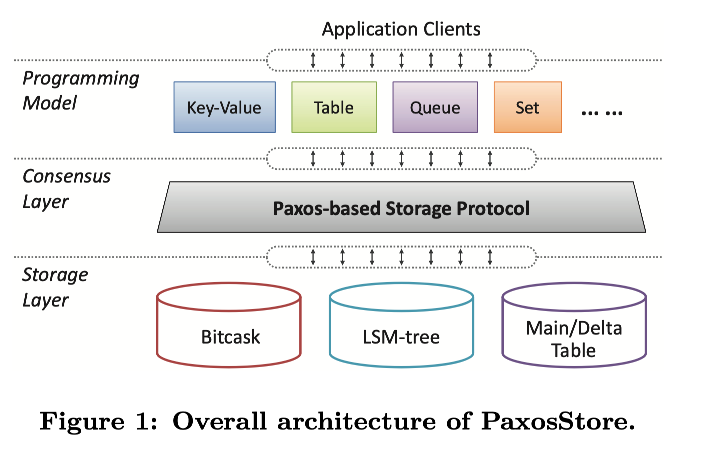
图 1 说明了 PaxosStore 的总体体系结构,该架构包含了三层。编程模型层提供了暴露给应用的各种数据结构,共识层实现了 Paxos-based 存储协议,存储层包含了基于不同存储模型的不同存储引擎,以使不同数据结构的性能最大化。PaxosStore 不同于传统存储系统主要在于将中间层的共识协议解耦出来,为底层多种数据引擎提供共识保证。
传统的分布式存储系统通常为了一种数据模型单独构建,并调整设计和实现以满足各种应用需求。然而,这就需要不同组件的各种复杂权衡。尽管组装多个现成的存储系统来满足存储要求的多样性也可以,但是这通常使整个系统难以维护而且不容易扩展。此外,每个存储系统将共识模型与存储模型耦合在一起,然后拼凑起来的组合系统分而治之结果可能使共识结果是错误的,因为每个单独的存储子系统各自保持共识。此外,使用多种数据模型的应用(会使用多个存储子系统)很难利用底层的子系统的共识保证,从而不得不自己单独实现一套自己的共识协议。
因为编程模型层的设计和实现在工程上并不难,所以主要表述了 PaxosStore 共识层和存储层设计
2.2 共识层 (Consensus Layer)

协议栈三层如图 2 所示
2.2.1 Paxos
存储协议基于 Paxos 算法使数据在多个 node 之间同步。理论上,Paxos 包含了两个阶段:准备阶段来达成准备工作的一致,接受阶段来达成最终的一致。按照惯例,Paxos 使用状态机表述。但是过度的状态设计以及复杂的状态转移会使得运行时很低的性能。
在 PaxosStore 中,我们摒弃了状态机的方式,而是使用半对称消息传递来解释 Paxos 过程。为此,我们首先定义一些符号
此节先略
2.2.2 PaxosLog
PaxosLog 在 PaxosStore 中作为数据更新的 write-ahead log。图 3 展现了数据结构,每个 log entry 由 Paxos 算法决定,可以被一个不变的序列号索引--entry ID,唯一递增。最大的 entry ID 表示版本。
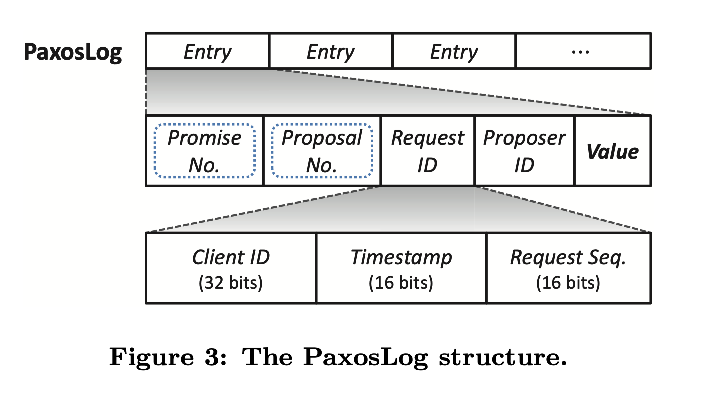
概念上,PaxosLog 实例可以被无限生成。实际上,通过 LRU 策略,异步删除过时的 log entries。除了数据 value 之外,每个 PaxosLog 包含 Paxos 关联的元数据,promise number m 和 proposal number n, 在 2.2.1 节中的 Paxos 算法使用,但是一旦 log entry 完成就会被丢弃(蓝色线框标记出)。此外,由于同一数据的多个副本主机可能同时发出写入请求,但是只有一个请求会被接受,proposer ID 附加到被选中的 value 上表明 value 的 proposer。Proposer ID 是 32 位的机器 ID,数据中心中唯一表征一个 node。用于预准备阶段的优化,如果当前写入可以跳过 pre-pare/promise 阶段,如果与上次写入的相同请求的原点,则符合写请求的局部性。此外,request ID 唯一标志与 value 相关联的写请求。用于防止重复写入(详细讨论在 3.3)。特别的,request ID 包含了三个部分:32 位的 client ID(比如 IPv4 地址)表明提出写请求的客户端,16 位的时间戳表明客户端本地时间,16 位的序列号表明客户端请求序列区分同一秒的请求
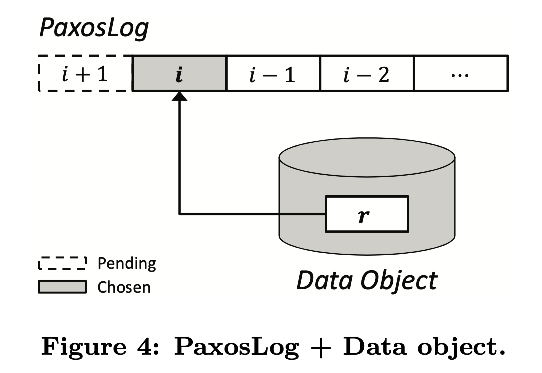
根据 write-ahead log 对于数据更新的机制,PaxosLog entry 在将值写入到存储引擎中时必须被处理。通常,PaxosLog 存储和数据对象存储是分离的,如图 4 所示,一次数据更新,两次有序的写 I/O :一次写 PaxosLog entry,接下来更新数据对象
PaxosLog 对于 Key-Value 数据的使用。 考虑下 k-v 存储,我们有两种优化,简化了 paxoslog 的构建和操作。
首先,取消了 data value 的存储,key-value 直接通过 paxoslog 存储,称为 paxoslog-as-value。在 Paxos-based 的 key-value 存储中,一对 k-v 与一个 paxoslog 关联。这样可以少一次 I/O,节省硬盘带宽。
其次,裁剪了 paxoslog 存储,只存储最新的两个数据历史,如图 5 所示,早于最新的数据被视为过时的,可以被删除,所以对于 k-v data 的 PaxosLog 长度恒定为 2。由于 PaxosLog 不会增大,所以可以消除对于数据更新对于内存和硬盘的影响,节省存储和计算计算。此外,简化了 k-v 数据的恢复。最新的 PaxosLog 包含了最新 k-v 数据的快照,可以在出问题时直接恢复数据。
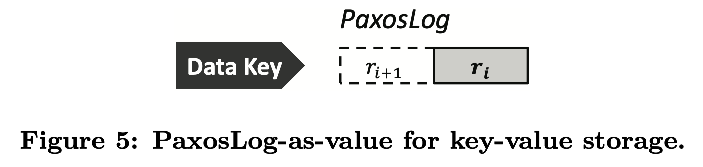
相比之下,正常数据的恢复需要对于 PaxosLog 在 last checkpoint 开始重放所有历史 log entry(如图 4 中表示),尤其是面向集合的数据结构,例如 list, queue,set
2.2.3 一致性读写 (Consistent Scheme)
PaxosStore 被设计为多地系统,在多个数据中心之上运行,同时采用 Paxos 协议以 leaseless 方式保证操作的共识,即每个节点可以同等处理数据。具体而言,通过所有副本节点的写作处理每个数据访问(读/写),并依赖 PaxosLog 实现数据的一致性保证。
一致性读。
一致性写。
2.3 存储层 (Storage Layer)
微信生产系统中的应用提出了多种数据访问的要求以及性能问题。在重组上一代存储系统之后,我们意识到在存储层支持多种存储模型是必要的。这启发了 PaxosStore 存储层的设计,基于不同的存储模型构建多个存储引擎。具体来说,BitCask 和 LSM-tree 是在 PaxosStore 中使用的两种主要模型,都是为了 key-value 存储设计:Bitcask 模型在单点查询更优,LSM-tree 在范围查询上更优。我们在存储层中实现了两种存储引擎,主要设计可用性,效率和可扩展性,不包括共识问题。将共识协议从存储层解耦出来称为中间层,使 PaxosStore 存储层的开发,调优和维护容易很多。存储引擎不仅可以单独调优,还可以协作一起工作,所以支持更加灵活的选项来支持应用特定的需求。
在 PaxosStore 中最常用的物理数据结构就是 key-value 和关系表。Key-value 原生被 Bitcask 和 LSM-tree 支持。根本上,PaxosStore 的关系表也被存储为 key-value 对,每个表是 value,被唯一 key 索引。但是,简单将表作为普通 key-value 会导致性能问题,因为大多数表都是频繁读取的,而且通常每张表包含成千上百个行,但是微信应用一次大多只访问其中一两行。因此,磁盘/SSD 和内存之间频繁的读写严重影响系统性能。为了解决这个问题,PaxosStore 采用了 differentail update 技术降低表更新的开销。为此,将表分解为两个元表:读优化的 main-table 管理表的主要数据,写优化的 delta-table 管理表的变化(比如更新,插入,删除)。因此表的访问是通过 main-table 的 view 结合 delta-table 管理的增量数据。更深一步,为了保持 delta-table 最小化(保留写友好的属性),会定时将增量数据合并回 main-table
3. 容错性与可用性 (Fault Tolerance and Availability)
3.1 容错 (Fault-tolerant Scheme)
3.2 数据恢复 (Data Recovery)
3.3 优化 (Optimizations)
4. 实现 (Implementation)
总结:
- 线程多导致同步状态负载,所以实现了 libco 协程,以同步的方式实现异步性能,除了 Paxos 算法本身显式异步编程
- 节点间通信,每台服务器以批量方式发送数据包,节省网络带宽。每个服务器还维护多个 socket 连接着同一机器,每个套接字轮流运行发送批处理的数据包,这样可以将数据的批处理分散到多个 socket 上
5. 评估 (Evaluation)
5.1 实验步骤
5.2 延迟
5.3 容错性
5.4 错误恢复
5.5 Effectiveness of PaxosLog-Entry Batched Applying
5.6 PaxosStore 在微信中的应用
5.6.1 服务即时消息 (Serving Instant Messaging)
5.6.2 服务社交网络 (Serving Social Networking)
6. Related Work
略
与 raft 不同的是,本文的 paxos 采用无租约设计,没有换主的不可用问题,可以不停机快速故障恢复
7. Conslusion
在本文中,我们详细解读了 PaxosStore,它是一个高可用性的存储系统,每秒可以承受数千万次的一致性读/写操作。PaxosStore 中的存储协议基于 Paxos 算法达成分布式共识,并在实际应用中对其进行了进一步优化,包括用于 key-value 存储的 PaxosLog-as-value 和 裁剪 PaxosLog 结构。基于细粒度数据检查点的容错方案使 PaxosStore 能够在故障时支持快速数据恢复,而不会导致系统停机。PaxosStore 已经在微信中实施和部署,为微信集成服务(如即时消息和社交网络)提供存储支持。
在 PaxosStore 的开发过程中,我们总结了几个设计原则和经验教训:
- 建议不要通过妥协的单一存储引擎支持存储多样性,而是设计这样的存储层,让它能够支持为不同存储模型构建的多个存储引擎。这种方法有助于开发者在操作维护的动态方面进行有针对性的性能调整。
- 除错误和故障外,系统过载也是影响系统可用性的关键因素。特别是在设计系统容错方案时,我们必须对过载引起的潜在雪崩效应给予足够的重视。 一个具体的例子是在 PaxosStore 中使用迷你集群组 (mini-cluster group)。
- PaxosStore 的设计大幅借鉴了基于消息传递的事件驱动机制,这可能会涉及逻辑实现方面的大量异步状态机转换。 在构建 PaxosStore 的工程实践中,我们开发了一个基于协程和 socket hook 的框架,以便于以 pseudo-synchronous 方式对异步过程进行编程。这有助于消除容易出错的函数回调,并简化了异步逻辑的实现过程。
8. References
略