You can enforce correct memory ordering on the processor by issuing any instruction which acts as a memory barrier.
描绘多级多 core 系统如下:
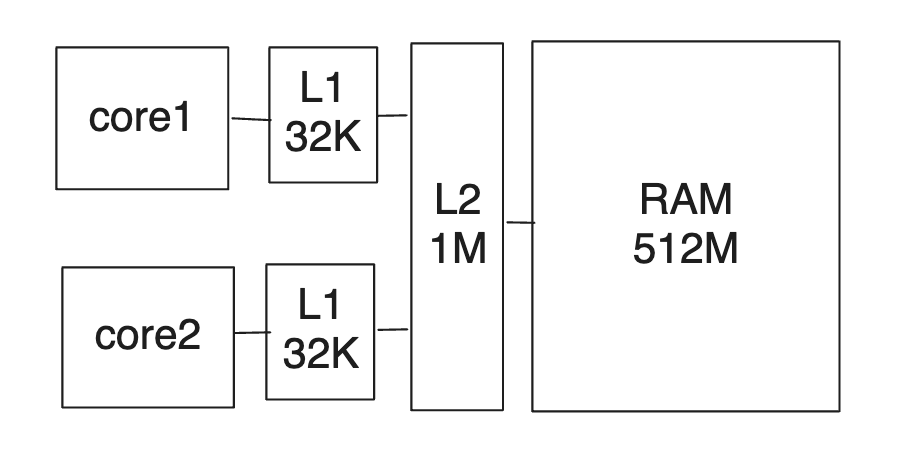 A multicore system is a bit like a group of programmers collaborating on a project using a bizarre kind of source control strategy.
A multicore system is a bit like a group of programmers collaborating on a project using a bizarre kind of source control strategy.
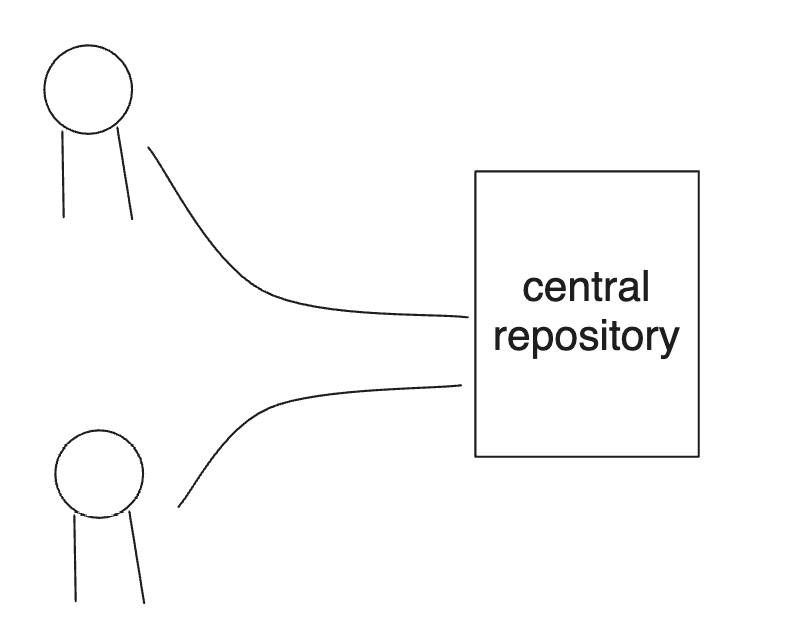 This represents a combination of main memory and the shared L2 cache. Every programmer has a complete working copy of the repository on his local machine. Our two programmers sit there, feverishly editing their working copy and scratch area, all while making decisions about what to do next based on the data they see - much like a thread of execution running on that core.
This represents a combination of main memory and the shared L2 cache. Every programmer has a complete working copy of the repository on his local machine. Our two programmers sit there, feverishly editing their working copy and scratch area, all while making decisions about what to do next based on the data they see - much like a thread of execution running on that core.
Which brings us to the source control strategy. There’s no guarantee about the timing or the order in which those changes leak back from the repository into his working copy. In this manner, loads are effectively reordered on their way out of the repository.
Now, if each programmer works on completely separate parts of the repository, neither programmer will be aware of these background leaks going on, or even of the other programmer’s existence. That would be analogous to running two independent, single-threaded processes.
四种 memory barrier 模型
LoadLoad
A LoadLoad barrier effectively prevents reordering of loads performed before the barrier with loads performed after the barrier.
In our analogy, LoadLoad fence instruction is basically equivalent to pull from the central repository.
if (is_published) {
LOADLOAD_FENCE(); // prevent reordering of loads
return value; // load published value
}StoreStore
A StoreStore barrier effectively prevents reordering of stores performed before the barrier with stores performed after the barrier.
In our analogy, the StoreStore fence instruction corresponds to a push to the central repository.
value = x; // publish some data
STORESTORE_FENCE();
is_published = 1; // set shared flag to indicate availability of dataLoadStore
There is no clever metaphor for LoadStore in terms of source control operations. The best way to understand a LoadStore barrier is, quite simply, in terms of instruction reordering.
Imagine a set of instructions to follow, there are a serial of load and store instruction, whenever he encounters a load, he looks ahead at any stores that are coming up after that; if the stores are completely unrelated to the current load, then he’s allowed to skip ahead, do the stores first, then come back afterwards to finish up the load.
On a real CPU, such instruction reordering might happen on certain processors if, say, there is a cache miss on the load followed by a cache hit on the store.
StoreLoad
A StoreLoad barrier ensures that all stores performed before the barrier are visible to other processors, and that all loads performed after the barrier receive the latest value that is visible at the time of the barrier. In other words, it effectively prevents reordering of all stores before the barrier against all loads after the barrier, respecting the way a sequentially consistent multiprocessor would perform those operations.