Bitcask: A Log-Structured Hash Table for Fast Key/Value Data
Posted 2021-03-02 00:00:00 ‐ 11 min read
译者注:豆瓣的 beansdb 使用 bitcask 概念 https://github.com/douban/gobeansdb
Bitcask 的起源与 Riak 分布式数据库的历史联系在一起。在 Riak 的 key/value 集群中,每个节点都使用插件化的本地存储;几乎任何 k/v 形式的引擎都可以来用。这种插件化的设计可以使 Riak 并行化使得存储引擎可以在不影响其他代码的情况下单独升级和测试。
已经存在很多这种 key/value 存储引擎,包括但不限于 Berkeley DB,Tokyo Cabinet, Innostore。在评估此类引擎时,我们考虑了许多目标,包括:
- 每条数据读写的低延迟
- 高吞吐,尤其是随机写入
- 处理远大于 RAM 吞吐能力的数据集的能力
- crash 友好性,不管是快速恢复还是不丢失数据
- 容易备份和恢复
- 简单,易理解的代码结构和数据格式
- 在重负载和大规模下的行为可预知
- Riak 易于使用的 license
实现其中的一些是容易的,但是实现所有特性很难。
就上述所有目标而言,没有现成的 key/value 存储系统。我们就这个问题与 Eric Brewer 进行讨论,他提出了一个关键 idea: hash table log merging: 这样做可能比 LSM-trees 快得多。
这促使我们以全新的视角探索了在 1980 和 1990 年代首次开发的 log-structured file system 中使用的一些技术。这次探索引出了 Bitcask 的发展,实现了所有上述特性。当 Bitcask 被作为 Riak 的底层为目标开发出来后,可以作为一个本地 key/value 存储引擎通用于其他应用。
最终使用的模型非常简单。一个 Bitcask 实例是一个目录,同一时间只有一个操作系统进程写入 Bitcask。你可以将此进程看做 database server。任何时候,只有一个文件是“活动的”,可以被服务器写入。当文件大小达到阈值,就会被关闭,然后一个新的“活动”文件就被创建出来。一旦文件被关闭,或者由于服务器关闭导致文件被关闭,该文件就被视为不可变的,不会再被服务器写入。模型如下图所示:
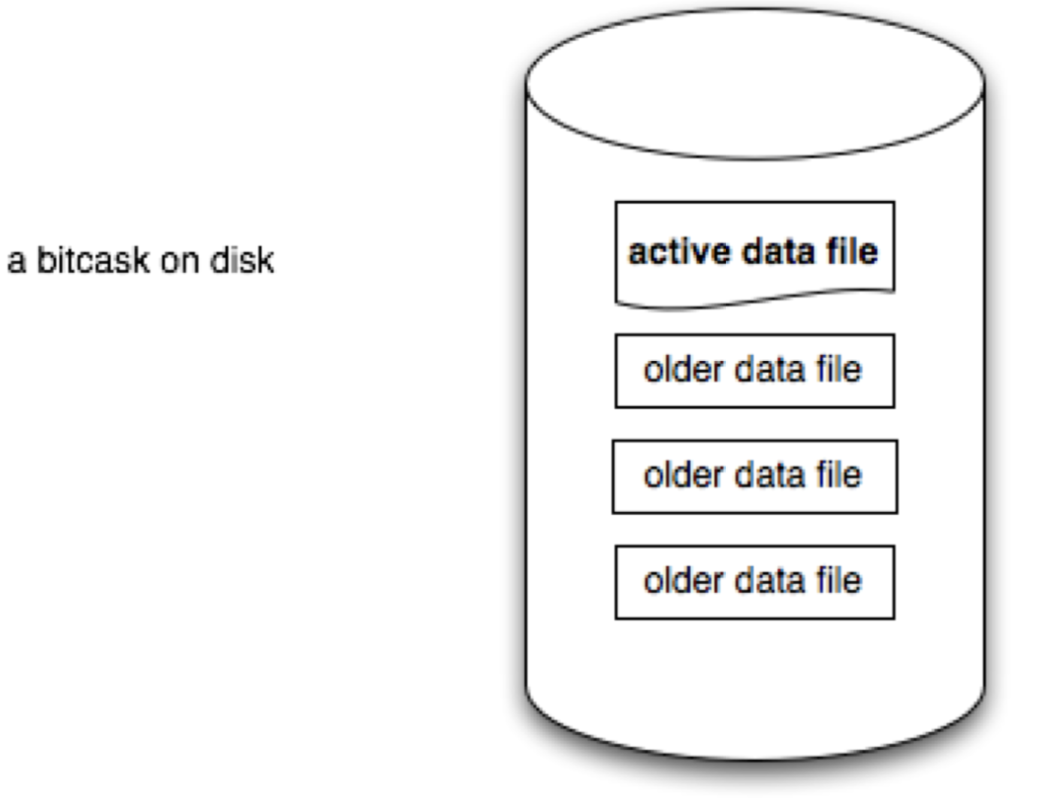
“活动”文件只能被追加写,这意味着磁盘不需要寻道,数据格式如下:
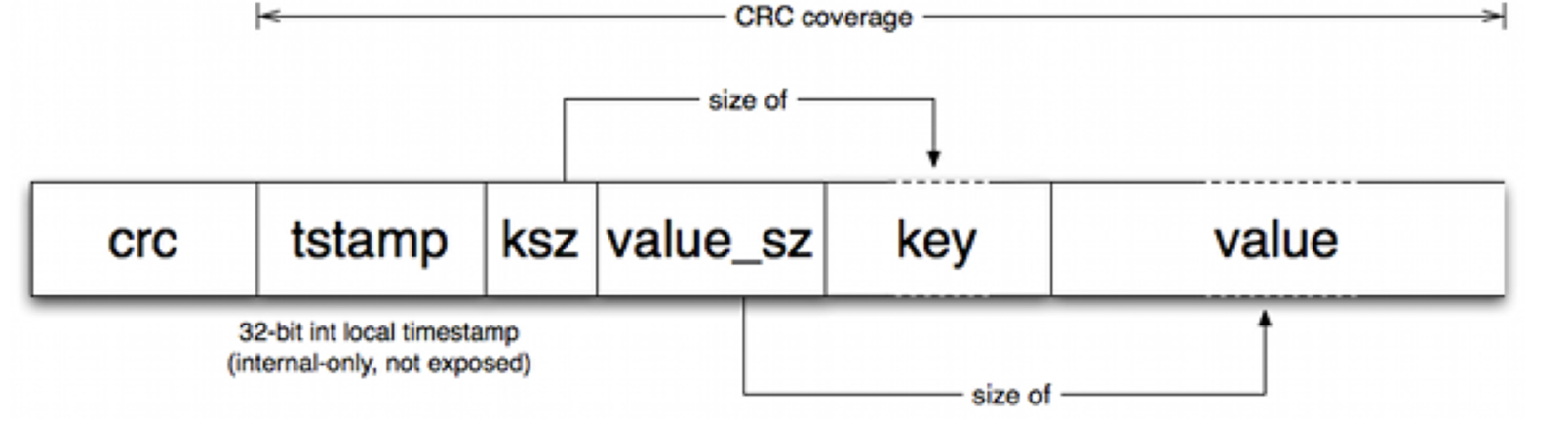
每次写入,文件尾部被追加一条记录。请注意,删除只是写入一个特殊的逻辑删除值,在下一次归并时会被删除。因此,Bitcask 数据文件就像下面的线性条目序列:

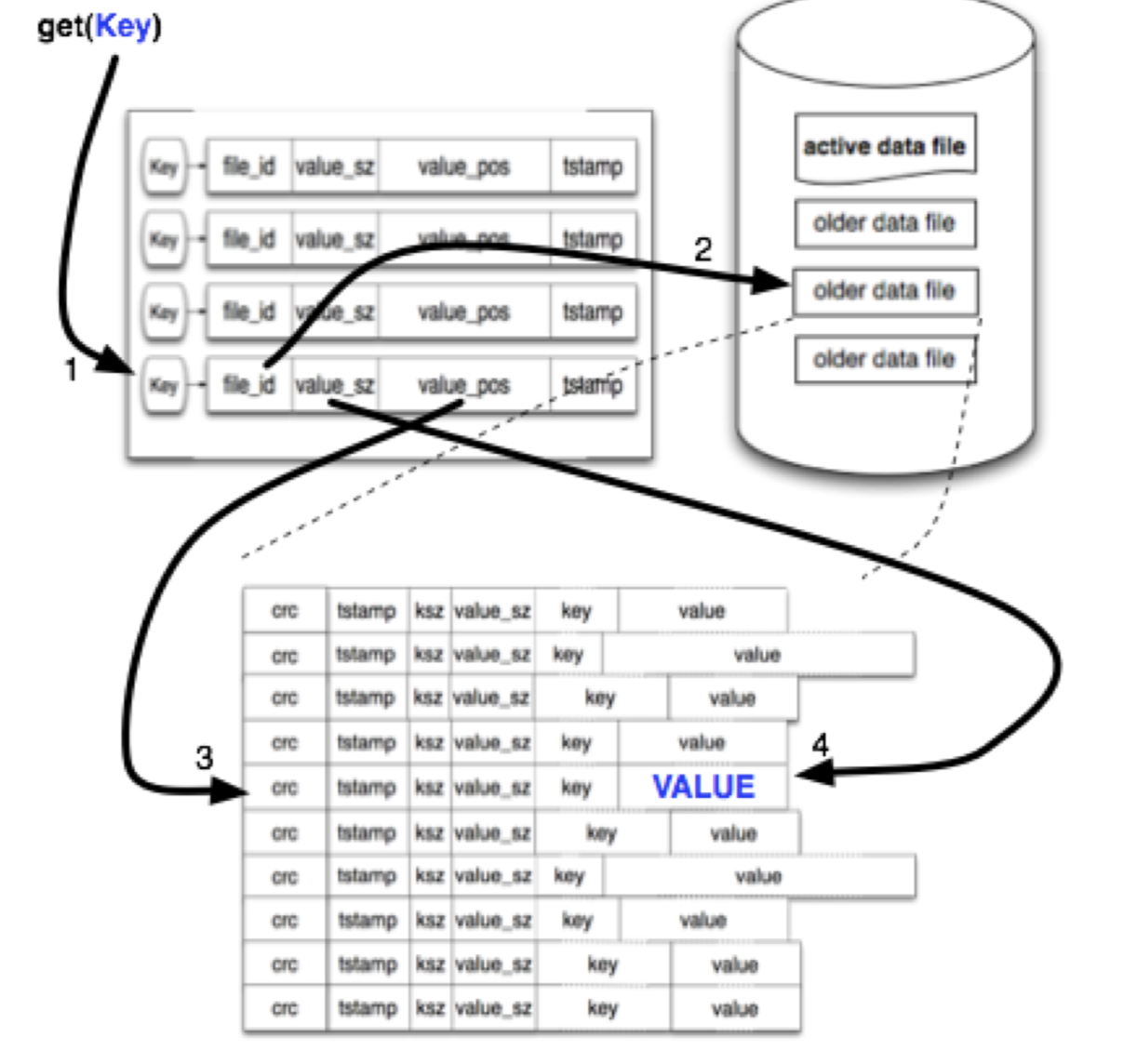
在每次追加后,内存中的数据结构被称为 "keydir" 会被更新。"keydir" 是一个 hash table ,描述了 Bitcask 中每个 key 的位置(固定结构)(file, offset, value size)

(译者注:file_id表示哪个文件,value_pos 表示offset, 以及value size表示从value_pos取多少数据)
当发生写入时,'keydir' 自动根据最新数据更新,老数据仍然存在与硬盘中,但是读取使用 'keydir' 记录的最新版本的数据信息。正如稍后我们看到的,归并过程会删除老数据。
读取数据很简单,不会超过一次硬盘寻道。我们在 'keydir' 中查找数据的 key 位置,然后使用获得的 file_id, value_pos, value_sz 直接读取数据。在很多情况下,操作系统的文件系统预读高速缓存使此操作比预期要快得多,读取过程如下图
这个简单的过程会随着使用时间占用越来越多的存储空间,因为我们一直在写入新数据。一个单独的“归并”进程用来解决这个问题,“归并”进程遍历所有“不活动”数据文件,然后生成一组只包含“活动”数据的文件。
完成此操作之后,我们将在每个数据文件旁创建一个“hint file”,包含对应数据文件的位置和值的大小。
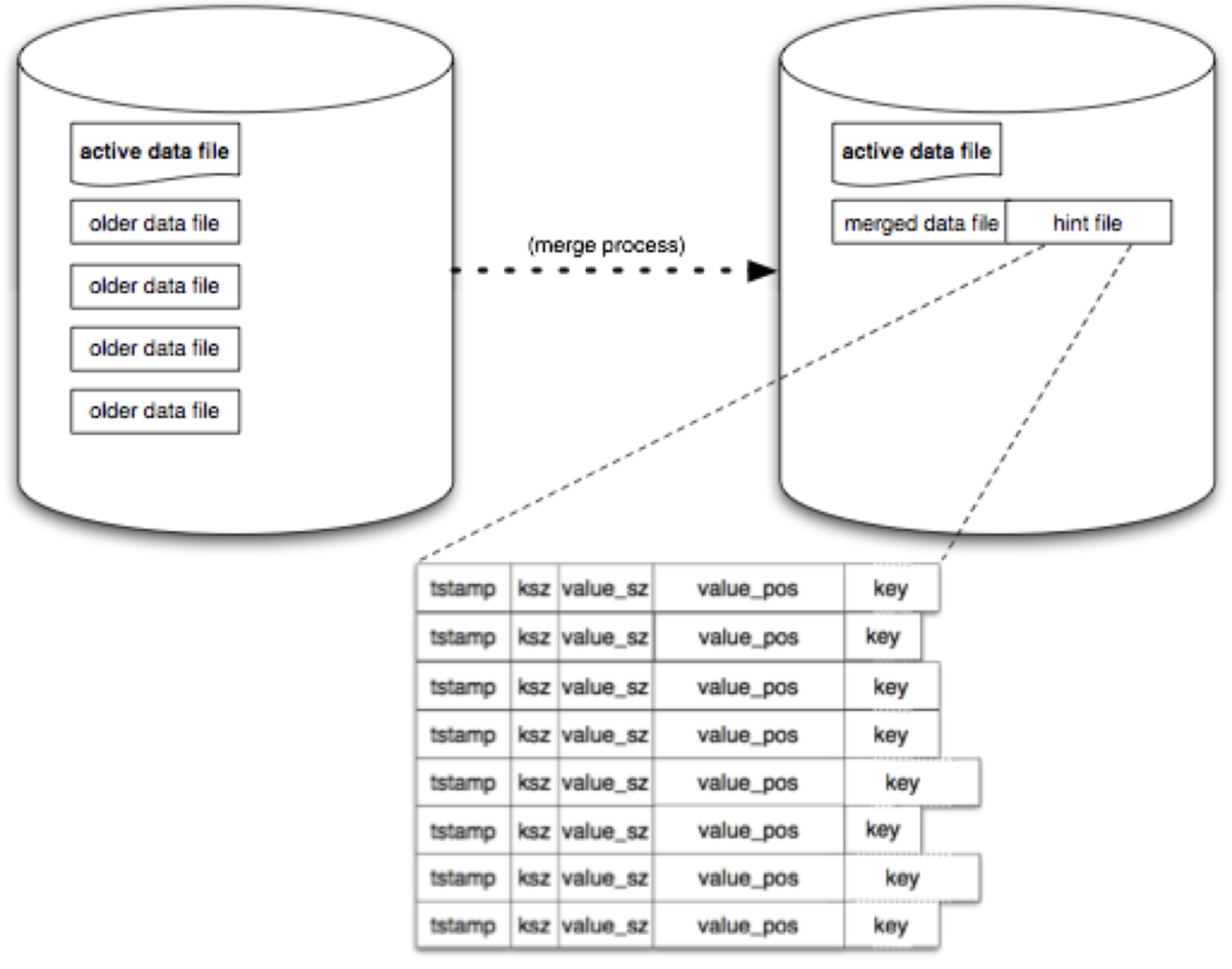
当 Bitcask 被 Erlang 进程打开时,会检查是否已经有其他进程已经打开当前 Bitcask,如果有,就会共享 keydir 信息,如果没有,会扫描所有数据文件,然后重建一个新的 keydir。如果数据文件有 ‘hint file’,可以加速这个重建过程。
上述就是 Bitcask 基本操作。显然,我们没有在这个文档中阐释所有操作细节;我们的目标是帮你了解 Bitcask 的概况。实际上还有一些细节讨论:
- 上面提到操作系统文件系统的cache可以提升读性能。我们也讨论了加入 bitcask 内部 cache 提升读性能,但是鉴于还没有实现,所以不清楚有多少回报
- 我们会尽快对 Bitcask 的各个接口做基准测试,但是最开始 Bitcask 就不是为了最快,而是在尽可能快的速度下拥有高质量并且简单的代码,设计和文件格式。不过还是要说,在最初的简单基准测试中,许多场景中 Bitcask 已经快于很多快速存储系统
- 最困难的实现细节对大多数外人来说也不感兴趣,因此在这份简短的文档中也没有比如 keydir locking 方案的描述
- Bitcask 没有对数据进行压缩,因为这样做的成本收益比很大程度上取决于应用
- 读写条目的低延迟 Bitcask 非常快。我们计划尽快做基准测试,但是在简单测试中,我们对 bitcask 达到目标很有信息
- 高吞吐,尤其是随机写 笔记本的低速硬盘测试,可以做到每秒 5000-6000 次写入
- 处理比 RAM 容量更大的数据集 上面提到的测试使用了超过 RAM 10倍的数据集,并且行为没有变化,这符合我们对于 Bitcask 设计的期望
- crash 友好,既能快速恢复又不会丢失数据 由于数据文件和提交log在 Bitcask 中是一样的,恢复很容易,无需重放,而且 hint file 可以加速重建过程
- 易于备份和恢复 在文件关闭后就不可变,因此备份可以使用操作系统的任何操作,恢复只需要将数据文件放置在所需目录即可
- 相对简单,易于理解的代码结构和数据格式 Bitcask 概念很简单,代码整洁,数据文件非常易于理解和管理。
- 在负载重或者数据量大的时候行为可预知 在大量访问负载情况下,我们已经看到 Bitcask 表现出色。到目前为止,只达到了两位数 GB 的数据,但是我们不久之后对其进行测试。Bitcask 的设计让我们预期在大数据量的情况下不会表现出太大不同,唯一可预见的就是 keydir 可能会随着数据量而变大可以会占用更多内存。实践中,这种限制不太有问题,即使存在数百万个 key,也只会占用 GB 级别的内存。
总而言之,鉴于最开始阐述的一组要求,Bitcask 是最适合这些要求的产品。